
Esporre i propri servizi applicativi con Semantic Kernel e ASP.NET Web API
Uno dei limiti principali degli esempi visti finora nell'uso di Semantic Kernel e Azure OpenAI, č stato l'accesso limitato alla sola knowledge interna del modello. Infatti, anche se abbiamo potuto rispondere a query basate sui dati e conoscenze giŕ presenti, non abbiamo avuto la possibilitŕ sfruttare servizi esterni in modo dinamico, come una nostra applicazione o database. Grazie all'uso dei plugin e delle function in Semantic Kernel, possiamo estendere le funzionalitŕ dei modelli GPT e rendere l'esperienza utente molto piů integrata con la nostra applicazione.
Un plugin, strettamente parlando, non č altro che una classe con uno o piů metodi che vogliamo esporre al model. Per esempio, immaginiamo di voler gestire degli ordini, potremo creare una classe simile alla seguente:
public class OrdersPlugin
{
[KernelFunction("search_orders")]
[Description("This functions allows you to search the orders in the database")]
[return: Description("A list of orders matching the search criteria")]
public async Task<IEnumerable<Order>> SearchOrdersAsync(OrderSearch search)
{
// .. altro codice qui ..
return orders;
}
[KernelFunction("add_order")]
[Description("This function allows you to add a new order to the database")]
[return: Description("The order with the generated Id")]
public async Task<Order> AddOrderAsync(Order order)
{
// .. altro codice qui ..
return order;
}
}Soffermiamoci sul primo dei due metodi: abbiamo decorato SearchOrdersAsync con alcuni attributi, primo fra tutti KernelFunction, che marca il metodo in questione come function, per l'appunto, specificandone il nome - in questo caso search_orders. In molti casi, il nome e la signature del metodo possono essere sufficienti al modello per capire come invocare la funzione in questione.
Ma una best practice č quella di essere il piů descrittivi possibile, cosě da minimizzare il rischio di invocazioni errate, e pertanto abbiamo utilizzato l'attributo Description per spiegare in maggiore dettaglio cosa fa questo metodo e quale sia il risultato. Anche gli altri oggetti coinvolti, quali Order e OrderSearch, possono essere descritti a loro volta, in modo che il modello sia piů preciso nel popolarli:
[Description("Search criteria for orders")]
public class OrderSearch
{
[Description("The product name to search for")]
public string Product { get; set; }
[Description("The start date of the search interval")]
public DateTime? StartDate { get; set; }
[Description("The end date of the search interval")]
public DateTime? EndDate { get; set; }
}
public class Order
{
[Description("The unique identifier of the order, it should be 0 for a new order")]
public int Id { get; set; }
[Description("The name of the customer who placed the order")]
public string CustomerName { get; set; }
[Description("The date when the order was placed")]
public DateTime OrderDate { get; set; }
[Description("The name of the product ordered")]
public string Product { get; set; }
[Description("The price of the product ordered")]
public decimal Price { get; set; }
}Una volta creato il nostro plugin e le classi correlate, dobbiamo aggiungerlo al Kernel, registrando una KernelPluginCollection nell'IoC container:
public static void Main(string[] args)
{
// .. altro codice qui ..
builder.Services.AddSingleton<IChatCompletionService>(sp =>
{
...
});
builder.Services.AddTransient<KernelPluginCollection>((serviceProvider) =>
new KernelPluginCollection()
{
KernelPluginFactory.CreateFromType<OrdersPlugin>("Orders", serviceProvider),
});
builder.Services.AddTransient<Kernel>();
...
app.Run();
}A questo punto siamo pronti per sfruttare il nostro nuovo plugin nelle chiamate alla ChatCompletion API. Prima di guardare il codice, perň, č bene rimarcare un concetto fondamentale: il modello GPT, di per sé, non č in grado di eseguire alcun codice custom. Tutto ciň che puň fare, č ritornare una speciale tipologia di risposta, che indica la richiesta di invocare un certo metodo con determinati parametri: č una nostra responsabilitŕ farlo, e poi restituire il risultato al modello cosě che possa sfruttarlo per elaborare la risposta all'utente.
Tipicamente questa procedura richiede l'implementazione di un workflow non del tutto banale, ma che per fortuna č completamente gestito da SemanticKernel senza che noi dobbiamo fare alcunché:
[HttpPost("{sessionId}/messages")]
public async IAsyncEnumerable<string> PostMessage(int sessionId, [FromBody] string message)
{
...
var settings = new AzureOpenAIPromptExecutionSettings()
{
Temperature = 0.5,
MaxTokens = 500,
ToolCallBehavior = ToolCallBehavior.AutoInvokeKernelFunctions
};
var result = _chatCompletionService.GetStreamingChatMessageContentsAsync(session.History, settings, _kernel);
...
}Il metodo del codice in alto č esattamente lo stesso dello scorso script 1490 (https://www.aspitalia.com/script/1490/Migliorare-Tempi-Risposta-GPT-Tramite-Streaming-Endpoint-ASP.NET-Core.aspx), ma in questo caso abbiamo aggiunto il setting ToolCallBehavior impostato a AutoInvokeKernelFunctions, cosě da lasciare a SemanticKernel l'onere di gestire queste invocazioni.
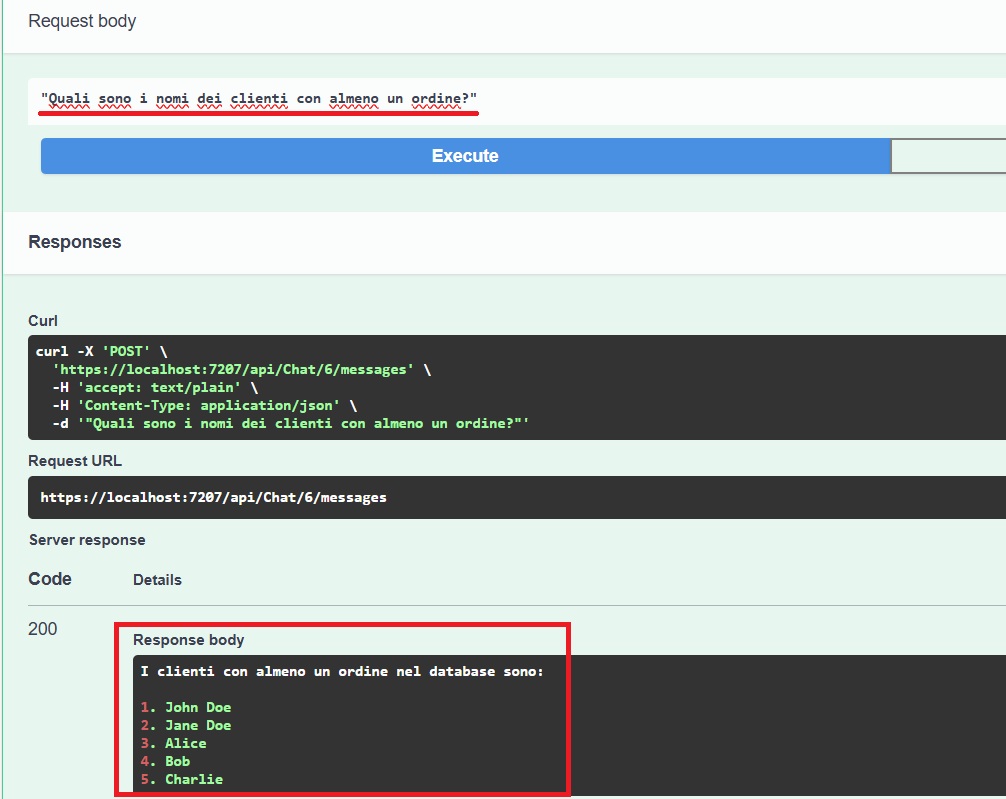
A questo punto, se proviamo a eseguire il codice, vedremo come il nostro chatbot sia finalmente in grado di rispondere in maniera corretta a richieste specifiche inerenti gli ordini:
Commenti

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
Approfondimenti
Eseguire i worklow di GitHub su runner potenziati
Creare agenti facilmente con Azure AI Agent Service
Eseguire query in contemporanea con EF
Rinnovare il token di una GitHub App durante l'esecuzione di un workflow
Gestire la cancellazione di una richiesta in streaming da Blazor
Inference di dati strutturati da testo con Semantic Kernel e ASP.NET Core Web API
Estrarre dati randomici da una lista di oggetti in C#
Utilizzare un numero per gestire la concorrenza ottimistica con SQL Server ed Entity Framework
Eliminare una project wiki di Azure DevOps
Utilizzare Hybrid Cache in .NET 9
Usare i servizi di Azure OpenAI e ChatGPT in ASP.NET Core con Semantic Kernel
Utilizzare Locust con Azure Load Testing



